10 6 月
毫無疑問,你希望你的網站被索引–但你怎麼能知道它是否被收錄?幸運的是,搜索引擎巨頭讓你很容易通過網站搜索來了解你的情況。下面是檢查的方法:
- 轉到Google的搜索引擎。
- 在Google的搜索欄中,輸入 “site:您的網域”。
- 當你在搜索欄下看時,你會看到Google的結果類別 “全部”、”圖片”、”新聞 “等。就在這下面,你會看到Google已經索引了你的多少個頁面的估計值。
- 如果顯示的結果為零,說明該網頁沒有被索引。
另外,你可以使用Google Search Console來檢查你的網頁是否被索引。建立一個帳號是免費的。以下是如何獲得你想要的信息:
- 登入Google Search Console。
- 點擊“索引”。
- 點擊“覆蓋範圍”。
- 您將看到已被收錄的有效頁面數。
- 如果有效頁面數為零,說明Google沒有對您的網頁進行索引。
你也可以使用Search Console來檢查特定的網頁是否被索引。只要把URL粘貼到URL檢查工具中。如果該頁面被索引,你會收到 “URL在谷歌上 “的信息。
- 讓你的網站被索引的最簡單方法是通過Google搜索控制台請求索引。要做到這一點,請到Google Search Console的URL檢查工具。將你希望被索引的URL粘貼到搜索欄,等待谷歌檢查該URL。如果該URL沒有被索引,點擊 “請求索引 “按鈕。
注意:Google曾在2020年10月暫停請求索引工具。然而,它剛剛在Search Console中被恢復!
然而,Google的索引需要時間。如前所述,如果你的網站是新的,它不會在一夜之間被索引。此外,如果你的網站沒有正確設置以適應谷歌機器人的抓取,它有可能根本就不會被索引。
無論你是一個網站擁有者還是一個網路營銷人員,你都希望你的網站被有效地索引。下面是如何實現這一目標的方法。
優化你的Robots.txt文件
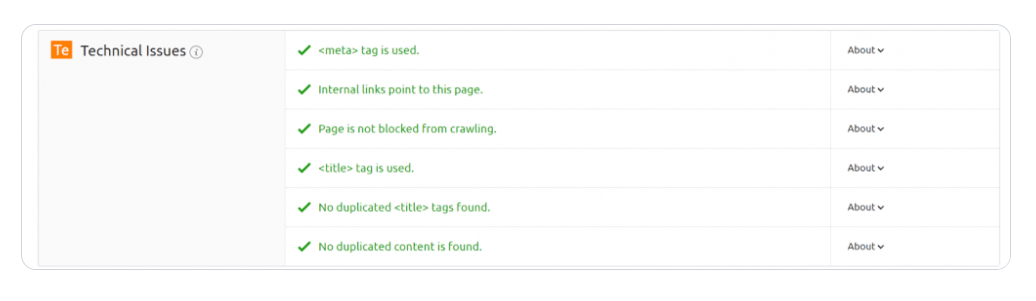
Robots.txt 是 Googlebot 識別為不應抓取網頁的指標的文件。來自 Bing 和 Yahoo 的搜索引擎蜘蛛也能識別 Robots.txt。您將使用 Robots.txt 文件來幫助爬蟲對更重要的頁面進行優先排序,這樣它就不會因請求而使您自己的站點過載。
儘管這一切聽起來有點技術性,但這歸結為確保您的網頁可抓取,您可以通過我們的On Page SEO Checker獲得更多幫助以找到這一點。它提供優化反饋,包括技術編輯,例如頁面是否被阻止抓取。
確保您所有的SEO標籤都是乾淨的
SEO標籤是另一種引導搜索引擎蜘蛛(如 Googlebot)的方式。您應該優化兩種主要類型的SEO標籤:
- 流氓 noindex 標籤:這些標籤告訴搜索引擎不要索引頁面。如果某些頁面未被收錄,則可能是它們沒有索引標籤。檢查這兩種類型:
- 元標籤:您可以通過查找“noindex 頁面”警告來檢查您網站上的哪些頁面可能有 noindex 元標籤。如果頁面被標記為 noindex,請刪除元標記以將其編入索引。
- X-Robots-Tag:您可以使用 Google 的 Search Console 查看哪些頁面的 HTML 標頭中有 X-Robots-Tag。使用上述 URL 檢查工具。進入頁面後,查找對“允許索引?”的響應。如果您在‘X‑Robots-Tag’http 標頭中看到“No: ‘noindex’ detection”字樣,則您知道有一個 X-Robots-Tag 需要刪除。
- 規範標籤:規範標籤告訴爬蟲是否喜歡某個頁面的某個版本。如果某個頁面沒有規範標籤,Googlebot 會識別出它是首選頁面和該頁面的唯一版本,並且會將該頁面編入索引。如果某個頁面確實有規範標籤,Googlebot 會假定該頁面有另一個首選版本,並且不會將該頁面編入索引,即使該其他版本不存在。使用 Google 的 URL 檢查工具檢查規範標籤。在這種情況下,您會看到一條警告,內容為“帶有規範標籤的備用頁面”。
仔細檢查您的網站架構以確保正確的內部連結和有效的反向連結
內部連結可幫助爬蟲找到您的網頁。非連結頁面被稱為“獨立頁面”,很少被收錄。站點地圖中列出的正確站點架構可確保正確的內部連結。
您的XML站點地圖列出了您網站上的所有內容,讓您可以識別未連結的頁面。以下是有關最佳實踐內部連結的更多提示:
- 消除nofollow內部連結。當Googlebot遇到nofollow標籤時,它會向Google發出訊號,表明它應該從其索引中刪除帶有標籤的目標連結。從連結中刪除nofollow標籤。
- 添加高級內部連結。如前所述,蜘蛛通過抓取您的網站來發現新內容。內部連結可加快流程。通過使用高排名頁面在內部連結到新頁面來簡化索引編制。
- 產生高質量的反向連結。 Google認識到,如果網頁始終被權威網站連結到,則這些頁面是重要且值得信賴的。反向連結告訴Google一個頁面應該被收錄。
優先考慮高質量的內容
高質量的內容對於索引和排名都至關重要。為確保您網站的內容具有高性能,請刪除低質量和性能不佳的頁面。
這使Googlebot可以專注於您網站上更有價值的頁面,從而更好地利用您的“抓取預算”。此外,您希望網站上的每個頁面都對用戶有價值。此外,內容應該是唯一的。重複的內容可能是 Google Analytics 的一個危險信號。
深入了解您的網站SEO
無論你是一個管理企業網站的站長,還是一個受雇的JavaScript程序員,或者是一個獨立的博客,基本的SEO都是必須知道的技能。搜索引擎優化聽起來令人生畏,但你不必成為一個專家就能弄清楚它。

